Troubleshooting Container App Jobs when using self-hosted CI/CD runners and agents
This post will cover some general and high level troubleshooting when trying to use Container App Jobs as a self-hosted runner or agent
Overview
Since you can run self-hosted runners for GitHub Actions and Azure Pipelines with Jobs, this has become a relatively popular option to use.
A walkthrough tutorial can be found here - Deploy self-hosted CI/CD runners and agents with Azure Container Apps jobs. The below sub sections will show potential troubleshooting steps using the above tutorial as the baseline.
General troubleshooting
Both CI/CD options (Actions and Azure Pipelines) and the publicly documented examples use KEDA to create jobs based off of what’s defined in the event driven scaler metadata. The implementation of a job acting as a self-hosted agent can be thought of as different concepts, such as:
- The scaler to create a job (eg., creating a pod or replicas)
- Executing the workflow/pipeline logic itself
If a commit is pushed to a repository (or a run is manually triggered) and a job pod or replicas are subsequentially created (depending on what metaData is defined for queue length - ex. targetWorkflowQueueLength or targetPipelineQueueLength), then we can deduce that the KEDA scaler is working as intended.
However, it is entirely possible, at this point, that the workflow/pipeline run itself can fail - or, fail to ever run. This does not necessarily mean the “job” failed - since at this point the workflow (eg., Actions .yaml or azure-pipelines.yml file) is being executed upon - and is limited more to the CI/CD process itself. If a workflow or pipeline is failing to run due to bad logic or other errors in the .yaml file itself - it would make more sense to troubleshoot this from a pipeline perspective rather than Container Apps. This can be ran locally for ease of use (see the local self hosted section at the bottom of this post).
If a job is successfully created, meaning that KEDA has picked up what has been defined in metaData, but - the pipeline/workflow run fails - a job will still show as “Successful” in “Execution History”.
This is because the job itself (eg., the container being ran in the pod/replica) did not crash, exit, or fail to start.
If a job is being shown as Failed, then at a high level, the failure may fall into any of the issues listed in the Troubleshooting failed job executions on Container App Jobs blog post and need to be investigated accordingly. Reviewing both ContainerAppConsoleLogs_CL and ContainerAppSystemLogs_CL is a good first bet - as runtime/application issues and/or configuration issues both can cause a “failed” job.
GitHub Actions
Below are some various scenarios that may affect jobs from running to completion.
Job “Failed” scenarios
Must not run with sudo:
This will look like the following in ContainerAppConsoleLogs_CL:
Must not run with sudo
When using the ghcr.io/actions/actions-runner image as a base to create the self-hosted runner - if you decide to not run as a non-root user prior to executing the container ENTRYPOINT, you will receive this message, unless you”
exportthe variable and valueRUNNER_ALLOW_RUNASROOT=1to allow the runner to run asroot- such as in your container entrypoint,
Otherwise, this will cause the container to exit upon startup - failing the job
Invalid configuration provided for token. Terminating unattended configuration.:
This may show if the PAT used is empty or malformed. Review ContainerAppConsoleLogs_CL for more details on the failure. For example, the below shows in a sccenario where there is an empty value provided to the PAT:
[RUNNER 2023-11-27 21:57:26Z INFO CommandSettings] Arg 'token': ''
[RUNNER 2023-11-27 21:57:26Z INFO CommandSettings] Flag 'unattended': 'True'
[RUNNER 2023-11-27 21:57:26Z INFO PromptManager] ReadValue
[RUNNER 2023-11-27 21:57:26Z ERR Runner] System.Exception: Invalid configuration provided for token. Terminating unattended configuration.
If following the tutorial walkthroughs - ensure the values passed as secrets and environment variables contain correct values.
For all other “Failed” jobs showing in the Execution History blade - view the Troubleshooting failed job executions on Container App Jobs blog post.
Job execution not appearing in Execution History blade
A job may not appear in the “Execution” blade due to KEDA scaler failures (assuming Event Driven is used in this context)
- A failure to scale would mean a pod or replicas would not be created
If KEDA is not explicitly failing (therefor creating a pod/replicas), then, there is the potential that the metaData provided to the scaler is targeting a different repository, repository owner, or others - that may be technically valid and exist - but not valid to what is intended to be targetted by the Container App Job. Also, potentially, the targetWorkflowQueueLength property is set to a higher value than expected.
Most times, a reason for KEDA failing to create pod/replicas would be logged in the ContainerAppSystemLogs_CL Log Analytics table. This can be used to potentially understand why this KEDA is failing to scale out replicas.
Below is an example of bad credentials due to one or more of the below issues:
the GitHub REST API returned error. url: https://api.github.com/repos/someuser/somerepo/actions/runs status: 401 response: {"message":"Bad credentials","documentation_url":"https://docs.github.com/rest"}
In terms of other reasons that would cause the scaler to fail, more specifically, incorrect values passed to KEDA’s Github Runner Scaler would typically be the root cause to this. Such as:
- Incorrect or non-existent
REPO_OWNER - Incorrect or non-existent
REPO_NAME - Incorrect or non-existent
REPO_URL(which concats bothREPO_OWNERandREPO_NAMEintoREPO_URL) - Incorrectly named/misspelled or non-existent
metaDatascale rule data - such as forowner, repos, runnerScope, and othersetc.
Additionally, if no workflow run is triggered (ex. by committing to the target branch in the workflow .yml, if specified) - then there is no workflow for KEDA to scale from. Ensure it’s clarified what method is kicking off pipeline runs - eg., manually triggered or triggered through commits
Workflow specific
There are many reasons why a workflow may fail to run. Note, that this is entirely separately from the job being able to scale up to x replicas as mentioned above - which at this point would be in a “Running” state.
Ensure that GitHub Action logging is always reviewed - especially in scenarios where the workflow is executing logic but failing later on.
Workflow is never executing:
A job may scale correctly based on what’s defined with KEDA, however, the workflow itself may never be executed. Review the GitHub Actions logging on the GitHub side in the workflow to see if there is any specific messages. If no messages are present - this may point more towards a configuration problem, such as:
- Personal Access Token:
- A token generated with improper permissions
- A token scoped to the wrong repository
If the job execution is pending on the workflow to run - which typically in the above cases it never will - then the job itself will eventually fail after the time specified in “Replica Timeout” with a DeadlineExceeded message. See the DeadlineExceeded blog section above for more information - Job timeouts - DeadlineExceeded vs. BackoffLimitExceeded.
Azure CLI usage:
Azure CLI is not installed in self-hosted Github Action runners. You would either need to use the “Install azure-cli” action, or, use an approach like the following:
# Self-hosted runners don't have az cli installed
- name: Install Azure cli
run: |
usermod -a -G sudo root
sudo apt-get -yy update && sudo apt-get install -yy ca-certificates curl apt-transport-https lsb-release gnupg
curl -sL https://packages.microsoft.com/keys/microsoft.asc | gpg --dearmor | tee /etc/apt/trusted.gpg.d/microsoft.gpg > /dev/null
AZ_REPO=$(lsb_release -cs)
echo "deb [arch=amd64] https://packages.microsoft.com/repos/azure-cli/ $AZ_REPO main" | tee /etc/apt/sources.list.d/azure-cli.list
sudo apt-get -yy update && apt-get install -yy azure-cli
Without installing the AZ CLI - this may manifest as unintiutive errors when trying to use the AZ CLI.
Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?:
As called out here - Jobs and self-hosted runners do not support running docker-in-docker commands.
Azure DevOps
Refer to the tutorial on how to create a Job that serves as a self-hosted pipeline agent in Azure DevOps, and the Keda doc for pipelines for information about configuring demands and other metadata settings for a pipeline triggered Job.
Job execution not appearing in Execution history blade
Just like in the GitHub Actions section, job execution not appearing in the Execution History blade, would generally happen due to KEDA failing to scale the pod/replicas. Refer to the GitHub Actions section for details on this.
Below is an example of a bad input value to organizationURL, which the KEDA Azure-Pipelines Scaler expects. The below example can appear due to a malformed or incorrect DevOps organization URI - such as having an extra “/” character at the end of the URI
error parsing azure Pipelines metadata: failed to extract organization name from organizationURL
More specifically, incorrect values passed to KEDA’s Azure-Pipelines Scaler would typically be the root cause to this. Such as:
- Incorrect or non-existent
ORGANIZATION_URL - Incorrect or non-existent
AZP_TOKEN - Incorrect or non-existent
poolNamevalue - Incorrectly named/misspelled or non-existent
metaDatascale rule data - such as fortargetPipelinesQueueLength, and others- orauthvalues likepersonalAccessTokenandorganizationURLetc.
This will also surface in the ContainerAppSystemLogs_CL table. Review the KEDA Azure-Pipelines Scaler documentation on metadata and auth usage.
Additionally, if no pipeline run is triggered (ex. by committing to the target branch in azure-pipelines.yml, if specified) - then there is no pipelines for KEDA to scale from. Ensure it’s clarified what method is kicking off pipeline runs - eg., manually triggered or triggered through commits
Job “Failed” scenarios
For job failed scenarios - review ContainerAppConsoleLogs_CL and ContainerAppSystemLogs_CL.
A job would be marked as failed either due to BackOffExceeded or DeadLineExceeded. Which either could be due to various issues such as image pull failures, container exiting with exit codes greater than 0, containers failing to be created, or others. Review the Troubleshooting failed job executions on Container App Jobs blog post for more information on this.
Workflow specific
Just like in the GitHub Actions section of this - there are many reasons why a pipeline may fail to run. Note, that this is entirely separately from the job being able to scale up to x replicas as mentioned above - which at this point would be in a “Running” state.
Ensure that Azure Pipelines logging is always reviewed when troubleshooting these scenarios.
You can additionally navigate to Project Settings -> Agent Pools - Agents - to see if an agent has been picked up or not. An agent running a build will update its status in this UI - below is an example:
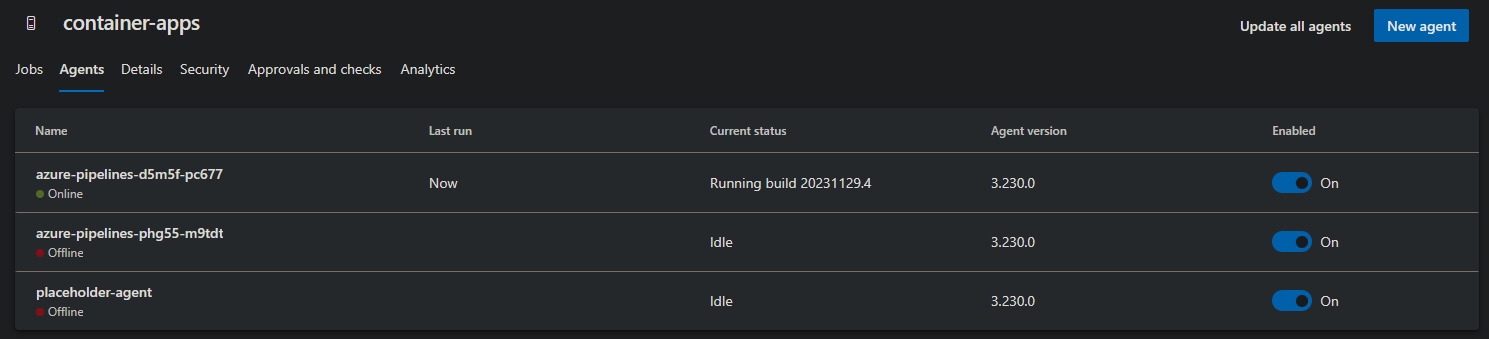
Workflow is never executing:
A job may scale correctly based on what’s defined with KEDA, however, the workflow itself may never be executed. This can happen for various reasons. Review the Azure Pipelines logging on the DevOps side in the pipeline to see if there is any specific messages.
Some other potential reasons:
- Personal Access Token:
- A token generated with improper permissions
- eg., Agent Pools having
readinstead ofread & manage
- eg., Agent Pools having
- A token generated with improper permissions
If the job execution is pending on the workflow to run - which typically in the above cases it never will - then the job itself will eventually fail after the time specified in “Replica Timeout” with a DeadlineExceeded message. See Job timeouts - DeadlineExceeded vs. BackoffLimitExceeded.
Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?:
As called out here - Jobs and self-hosted runners do not support running docker-in-docker commands.
The agent request is not running because all potential agents are running other requests. Current position in queue: 1:
This may show if a pipeline run is kicked off (ex. manually or through a commit) but there is no Container App Job (pod or replicas) created yet to handle the Azure DevOps job run.
This could be due to:
- KEDA is still polling the Azure Pipelines resource - for instance, a polling period ended (such as 30 seconds), a run was kicked off, which means this will be picked up on the next poll - if this is the case, the pipeline run should start running within the minute
- A job pod/replica is failing to be created, either it is:
- Failing due to a runtime issue, like crashing/exiting, failing to start, or other issues
- KEDA is failing to scale the resource - such as if bad credentials or options for the
azure-pipelinesscaler was provided
Placeholder Agent:
-
The placeholder agent that is created in the tutorial must remain present in DevOps. Triggering the event-driven Job creates a temporary agent in the DevOps agent pool so that the Job can interact with the pipeline.
-
NOTE: The concept of needing a placeholder agent is through KEDA - which is called out here. Failure to have a placeholder agent will cause these jobs to not run.
Demands:
-
If you configure a demand in the DevOps pipeline, the demand name must match the name of a “capability” that is present in the placeholder agent. Think of capabilities as key/value properties that are part of the agent. Steps for how to navigate to the capababilities section of a DevOps agent can be found here.
-
A demand can either be the name of a capability (e.g. Agent.OS), or it can also contain a condition for the value of the capability (e.g. Agent.OS -equals Linux). The capabilty name specified in the pipeline’s demands must match a capabilty name in the placeholder agent. For example, if the pipeline contains the following demands, the placeholder agent must have a capability named HOME, and also have a capability named Agent.OS with a value of Linux, in order for the Job to trigger,
pool:
name: container-apps
demands:
- HOME
- Agent.OS -equals Linux
- On the event-triggered Job, you can optionally configure additional conditions for demands, so that the Job will only trigger if the Azure Devops build pipeline’s demands consist of a subset of the Container App Job’s demands.
For example, if the Container App Job contains the following demands:
"metadata": {
"demands": "Home,Agent.OS -equals Linux",
The above is
demandswhich is a part of the Azure-Pipelines KEDA metadata
… and if the Azure Pipeline contains a demands section, then the pipeline’s must consist of at least one demand that is specified in the Container App Job in order to trigger the Job. Here is a sample pipeline demands section that would meet the criteria to trigger the Job:
pool:
name: container-apps
demands:
- Agent.OS -equals Linux
Notes:
- If the demands section is not present in the Pipeline, the demands settings on the Job will be ignored and the Pipeline will trigger the Job.
- If specifying multiple demands in the Container App Job, be sure not to put a space between the comma and the next demand, otherwise the Job will not trigger.
Parent
- The “parent” property in the Azure-Pipelines KEDA scaler metada cannot be used for Container Apps and Jobs, because it is references a Kubernetes section that is not accessible or configurable for Container Apps and Jobs.
Running jobs for self-hosted agents locally
It is possible to run Event Driven Jobs locally - if trying to troubleshoot relatively simple scenarios or for proof-of-concepts prior to deployment on Azure Container Apps. You can connect these locally to your Azure Pipelines or GitHub Actions resources.
You can still follow the tutorial for the Azure Pipelines agent and GitHub Actions Runner on setting up the other requirements - like PAT tokens and placeholder pools for Azure Pipelines.
This has a few prerequisites:
- Having a Kubernetes cluster - you can easily enable Kubernetes on Docker Desktop
- Go to Docker Desktop - Click the “Gear” icon in the top right -> Kubernetes -> Select “Enable Kubernetes” -> Apply & restart
- Installing Helm
- Windows: Install via Chocolatey:
choco install kubernetes-helm - Linux (Debian/Ubuntu):
curl https://baltocdn.com/helm/signing.asc | gpg --dearmor | sudo tee /usr/share/keyrings/helm.gpg > /dev/null sudo apt-get install apt-transport-https --yes echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/helm.gpg] https://baltocdn.com/helm/stable/debian/ all main" | sudo tee /etc/apt/sources.list.d/helm-stable-debian.list sudo apt-get update sudo apt-get install helm - Validate this is installed with
helm -v
- Windows: Install via Chocolatey:
- Install KEDA
- With Helm installed, you can easily install KEDA into your Docker Desktop cluster
helm repo add kedacore https://kedacore.github.io/chartshelm repo updatehelm install keda kedacore/keda --namespace keda --create-namespace
- After a successful KEDA installation you should see KEDA pods in your Docker Desktop cluster
- With Helm installed, you can easily install KEDA into your Docker Desktop cluster
You can now use the below ScaledJobs to deploy to your .yamls to and use as local self-hosted agents. Ensure the rest of the tutorial is followed for setting up specific implementations of Azure Pipelines or GitHub Actions:
Azure Pipelines
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: azure-pipelines
namespace: default
spec:
minReplicaCount: 0
maxReplicaCount: 1
jobTargetRef:
template:
spec:
containers:
- name: azure-pipelines
env:
- name: AZP_TOKEN
value: "your_pat_token"
- name: AZP_URL
value: "https://dev.azure.com/someorg"
- name: AZP_POOL
value: "container-apps"
image: azure-pipelines-agent:1.0
imagePullPolicy: IfNotPresent
restartPolicy: Never
triggers:
- type: azure-pipelines
metadata:
organizationURLFromEnv: "AZP_URL"
personalAccessTokenFromEnv: "AZP_TOKEN"
poolName: "container-apps"
GitHub Actions:
apiVersion: v1
kind: Secret
type: Opaque
metadata:
name: github-auth
data:
personalAccessToken: "a_base64_encoded_string"
---
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: github-trigger-auth
namespace: default
spec:
secretTargetRef:
- parameter: personalAccessToken
name: github-auth
key: personalAccessToken
---
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: github-runner
namespace: default
spec:
minReplicaCount: 0
maxReplicaCount: 1
jobTargetRef:
template:
spec:
containers:
- name: github-runner
env:
- name: GITHUB_PAT
value: "github_pat_token"
- name: REPO_OWNER
value: "someowner"
- name: REPO_NAME
value: "somerepo"
- name: REPO_URL
value: "https://github.com/$REPO_OWNER/$REPO_NAME"
- name: REGISTRATION_TOKEN_API_URL
value: "https://api.github.com/repos/$REPO_OWNER/$REPO_NAME/actions/runners/registration-token"
image: github-actions-runner:5.0
imagePullPolicy: IfNotPresent
restartPolicy: Never
triggers:
- type: github-runner
metadata:
ownerFromEnv: "REPO_OWNER"
runnerScope: "repo"
reposFromEnv: "REPO_NAME"
targetWorkflowQueueLength: "1"
authenticationRef:
name: personalAccessToken
These can both be deployed locally to your cluster with kubectl apply -f nameofyourfile.yaml
NOTE: The GitHub Actions example expects a base64 encoded string secret. You can encode your string with the following and copy/paste the value where it says “a_base64_encoded_string” - use the command
echo -n "github_pat_11aabbc" | base64


