Container Apps - Backoff restarts and container exits
This post will discuss ContainerBackOff events and container exits events
Overview
This post talks about ContainerBackOff events and container exit events - which may show up as Error or ContainerTerminated in the Reason column of the ContainerAppSystemLogs_CL / ContainerAppSystemLogs tables for Log Analytics or Azure Monitor, respectively.
Back off events:
ContainerBackOff or messages of Persistent Failiure to start container is essentially the same thing backoff-restart events in Kubernetes. Where the container is continuously failing to be started in a pod or replica.
Container exits:
Container exits are what you may imagine - the container was able to start in a pod or replica but at some point in time after it exited, typically with a status code thats greater than 0 (indicating failure)
This will also appear in the ContainerAppSystemLogs_CL / ContainerAppSystemLogs tables - typically with a Reason of ContainerTerminated or Error. The message itself may look like Container 'my-container' was terminated with exit code '137'
Reasons for failure
Note that you generally may see both Persistent Failiure to start container and Container 'my-container' was terminated with exit code 'some_exit_code' together.
Although, these two may not be mutually exclusive, if for instance, the container exited and a new pod was created and the next attempt at container startup in the new pod was succesful. In that case, you’d only see Container 'my-container' was terminated with exit code 'some_exit_code'.
If in the new pod/replica, the container continued to be unsuccessful with starting - then you’d see both messages.
Application related
Most of the times, these messages may be application related. The reason for failure completely depends on the application logic and configuration required for it.
Since that is the case, and reasons can be almost limitless, it is important to always review Log Stream and ContainerAppConsoleLogs_CL / ContainerAppConsoleLogs tables (depending if Azure Monitor or Log Analytics is used). Assuming that the application is writing to stderr, normally, some indication of failure would be in here.
Below is an example, where ContainerAppSystemLogs_CL most shows Persistent Failiure to start container. When we look in ContainerAppConsoleLogs_CL, we see the reason why:
(ContainerAppSystemLogs_CL)
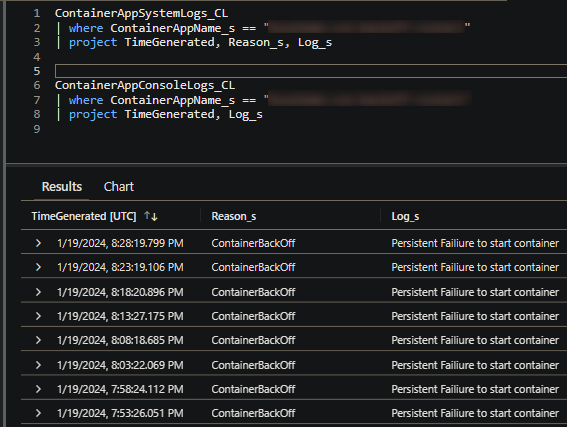
(ContainerAppConsoleLogs_CL)
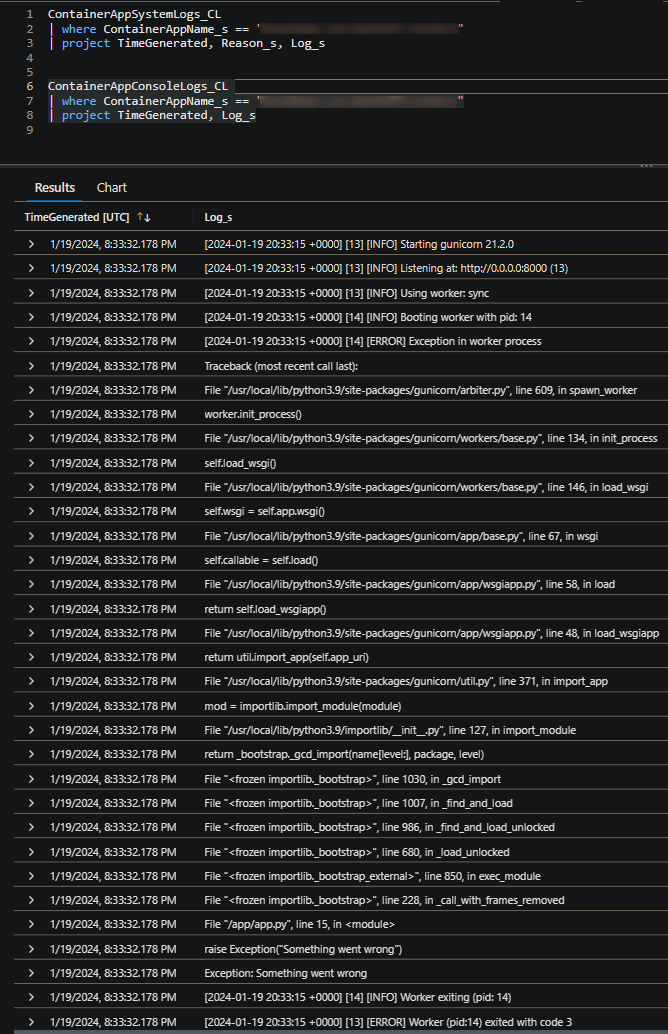
In this example, this was an exception thrown by raise Exception() in this applications app.py, acting as the entrypoint. Given the location its called from, this causes the application to exit at every startup attempt.
Other examples may generally include:
- Missing environment variables, secrets or other required configuration for an application to function in a deployed environment (or containerized image, in general)
- Startup logic that connects to external dependencies, in which is failing
- Authentication to external resources, which may be failing
- General fatal errors - like uncaught exceptions, or, exceptions that ultimately exit with a code 1 or greater
- etc.
Container exits:
An application exiting with a specific exit code may look like something below. You want to take the same approach to investigating application logs. If for some reason this is not being written to stdout/stderr - consider enabling more verbose logging while attempting to reproduce the issue. Otherwise, tracking down the issue may be more tough.
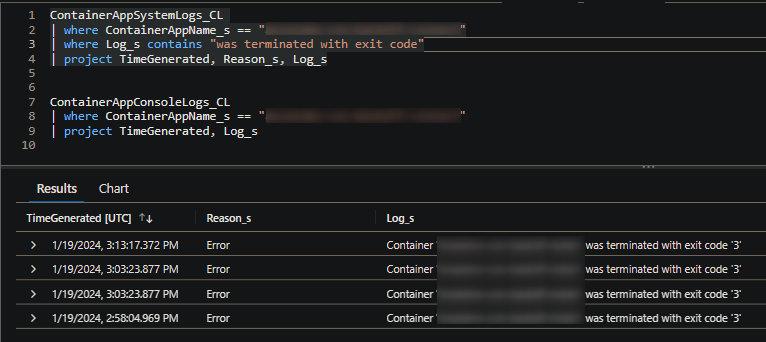
Below is a table that can generally be referenced for exit codes:
| Code | Description |
|---|---|
| 0 | An exit code 0 can signify successful completion of the task executed within code. This may not necessarily be bad. If an application is exiting with an exit code of 0, review if this is expected for the application as this is likely being set within code or a referenced library. A call to exit() may cause the container to exit regardless of being successful or not. |
| 1 | An exit code 1 can signifiy an application error caused the container to exit. This can be any fatal runtime error, or an invalid reference, such as a file being referenced that does not exit within the container. This is a generic catch all application exit error code. |
| 2 | An exit code 2 can indicate a missing keyword, command, or invalid syntax in an invoked shell or script. This can indicate a permissions issue as well. |
| 100 | An exit code 100 may be common with MongoDB (mongod). This may be due to an unhandled exception. Review if this container is a MongoDB container. |
| 125 | An exit code 125 can point to an issue with the run command. Such as an undefined flag, an issue between the container runtime engine and the OS, or the user in the defined Docker Image does not have sufficient permissions on the machine. |
| 126 | An exit code 126 may mean a command used in the container cannot be invoked. Possibly due to syntax issues or an invalid/missing dependency of the command |
| 127 | An exit code 127 means the command invoked refers to a non-existent or non-accessible file or directory. |
| 128 | An exit code 128 is an invalid argument to exit. The allowed range is only whole integers between 0-255. |
| 134 | An exit code 134 means the container abnormally terminated itself, closed the process and flushed open streams. A library or specific process may have called SIGABRT. |
| 137 | An exit code 137 means the container received a SIGKILL signal from the OS. This is forceful termination. This can happen in k8s OOM (Out of memory) scenarios, resource contention issues on the node, or other various k8s-specific scenarios. This can also occur if a SIGTERM was sent but the container did not shutdown after 30 or more seconds. OOM is not mutually exclusive to a 137 code |
| 139 | An exit code 139 indicates a SIGSEGV, or Segmentation Fault. This can happen due to code issues, issues between executables in the application and shared libraries/object files (.so files), or incompatability with libraries and the OS. |
| 143 | An exit code 143 indicates a SIGTERM, or graceful shutdown. This can happen due to Kubernetes terminating the pod, such as due to inactivity with minReplicas set to 0, or if there is node movement occurring and the pods need to be shut down. |
| 255 | An exit code 255 indicates an Exit Status Out Of Range. The container (application) entrypoint stopped and returned that static. Investigation through logs will be needed to see why the container entrypoint exited with this status code. |
It is possible to have other exit codes that are not on this list. The closest to “standardized” exit codes is what’s defined here - tldp.org - exit codes. Otherwise, a developer could use their own meaning for exit codes. Always review application logs in this case.
Platform related
Most of the common exit codes that may be seen that may have had a cause by the platform is related to exit code 137. As mentioned above, this can happen if SIGTERM was sent to the container but it not shut down within the period defined by “Termination Grace Period” - in which case, a 137 / SIGKILL is sent.
Aside from this, vCPU or memory constraints being hit on the node the pod or replica is running on will kill the container with a 137 code and also may show the below:
Maximum Allowed Cores exceeded for the Managed Environment. Please check https://learn.microsoft.com/en-us/azure/container-apps/quotas for resource limits
This is resource contention related, which won’t be covered in this article.
In other circumstances, a possibility of a 143 exit code in scenarios where a pod or replicas are scaled down (most likely back to 0) may show, as well. A blog post which goes further into this and why it can happen can be found at Maximum Allowed Cores exceeded for the Managed Environment
Another platform related reason for exit codes, specifically exit code 137 with Reason of Evicted, is if Pod or container exceeded local ephemeral storage limit
issues happen.


