Handling unexpected job terminations on Azure Container Apps
This post goes over situations where you may notice jobs being terminated or stopped briefly and some things that can be done to help alleviate interruptions.
Overview
With any PaaS service, there may be events going on under the hood, such as platform upgrades or unexpected node activity that may interrupt a job. The same could be said in essentially any environment.
With long running jobs in particular (eg. ones that are hours long, or may take even more than a whole day to complete), the chance at interruption may increase slightly and these also typically may be more sensitive to any kind of process restart. This can be exaggerated by the fact processing needs to be done, such as with messages or blobs.
Where to look for activity
Logging and the Execution history blade will show your job events. Both of these should be utilized together to give more insight. You may have 3rd party/external logging set up that sends logs to a destination, which should be looked at as well. Below is an example of the Execution history blade - the hyperlinks under the Logs column will take you to the Logs blade and run a query automatically targetting that job exuection ID.
Logs can be queried in the Logs blade manually as well. The Status column will show the status of that particular execution and what it ended with.
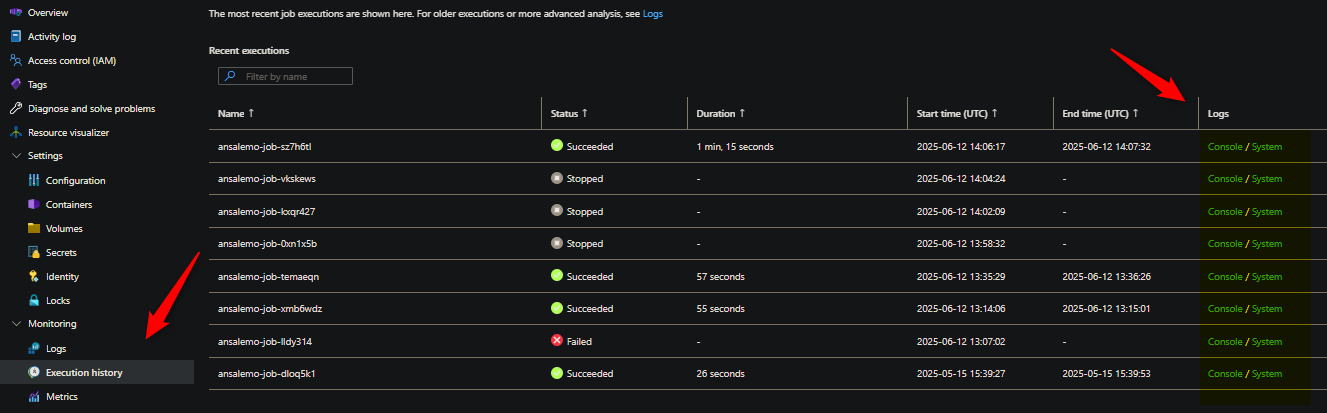
These logs will not show an explicit platform upgrade event. But the system logs will show typical container/pod/scheduling/other events that can help you determine what may have occurred if you noticed interruption.
NOTE: Platform maintenance notifications are an opt-in and not enabled by default
Application logs, either via the Console logs or a 3rd party provider destination, is imperative to look at as well. There may be cases where an application hits unexpected behavior at runtime which causes a process exit or similiar events. You’d want to rule out this possibility instead of only purely looking at system logs.
More information all of this can be found in the below links:
- Application Logging in Azure Container Apps
- Log storage and monitoring options in Azure Container Apps
- Set up alerts in Azure Container Apps
- Monitor logs in Azure Container Apps with Log Analytics
Ways to lessen impact
Planned Maintenance Windows
This only applies to applications using Dedicated Workload Profiles or applications in a Consumption-only environment
- This does not apply to applications using Consumption profiles
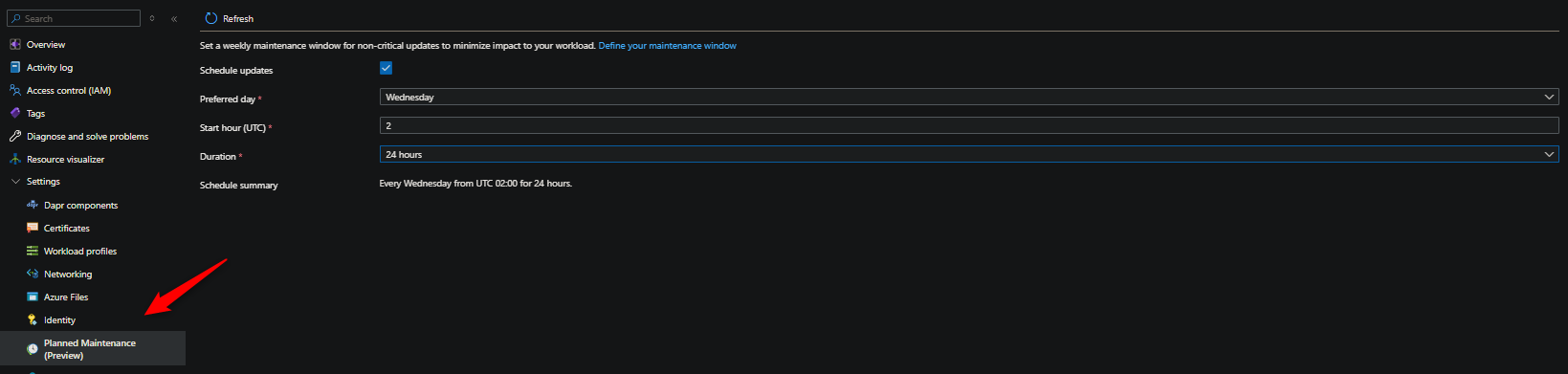
This is a very low effort way to avoid a job interruption - especially if you have a standard execution time, window, or day. Enabling planned maintenance windows can be done by following the steps here. You can view maintenance history by using Diagnose and Solve Problems on the Container App Environment and following the steps here.
Since Planned Maintenance doesn’t apply to Consumption profiles, consider moving jobs to a Dedicated Profile to make use of this feature.
There may be times that even with a Planned Maintenance window a chance of interruption can occur during critical updates (or behavior such as application issues or other anomolies). See below for other application-level handling that can be done.
Application cleanup
POSIX signals are sent to containers in a pod when shutdown events occur, gracefully or forced. Examples would be during platform upgrades or other node activity that would require shutting down the containers in the job pod and to reschedule said execution. The application logic in your job can make use of these by listening for these events.
This will completely depend on the application logic, but an example of this using apps can be found here - Graceful termination on Container Apps
This can, and should be used, to properly clean up any logic and avoid unintended side effects of process shutdowns prior to the expected job completion time.
Checkpointing logic for processing
Another concept that can be done is “checkpointing”. This again completely relies on application logic and can be implemented in almost infinite number of ways. The idea is that for jobs that require processing of an entity, and to avoid reprocessing data needlessly, is to be aware of a last known “checkpoint” in the data to pick up from.
An already existing concept of this is done by Azure Event Hubs - Checkpointing. Dapr also uses this for it’s PubSub components where EventHub is used.
For example, a job is expected to run for 8 hours. At hour four (4), it’s shutdown due to an upgrade. If checkpointing is in place, it will have some form of state to be aware of what was last processed in whatever queue/message/storage/table it’s reading from - and pick up from there. That way impact is lessened.
Below is an example of this with a job written in Go.
- Upon startup, it lists all blobs in the specified container
- Upon completion, it “checkpoints” the last iterated blob and writes it to another container named “checkpoint”. The
checkpoint.txtfile contains the name of the last blob - If the job is shutdown prematurely, it’ll listen for typical signals and write the last known blob to the checkpoint. Otherwise, it completes as normal (but still logs the checkpoint)
Note, this example doesn’t actually attempt to implement “processing” but is mimicking this. The real goal is to show some form of checkpointing the last blob (or data) accessed.
...other truncated code
var lastAccessBlob string
// Iterate over blobs
func manageBlobs(url string, containerName string, ctx context.Context, credential *azidentity.DefaultAzureCredential) {
// Create a client
client, err := azblob.NewClient(url, credential, nil)
handleError(err)
pager := client.NewListBlobsFlatPager(containerName, nil)
for pager.More() {
resp, err := pager.NextPage(ctx)
handleError(err)
for _, blob := range resp.Segment.BlobItems {
time.Sleep(2 * time.Second)
zap.L().Info("Sleeping for 2 seconds before logging blob data")
zap.L().Info("Blob found", zap.String("name", *blob.Name), zap.Time("last modified", *blob.Properties.LastModified))
lastAccessBlob = *blob.Name
}
}
}
// Check for an existing checkpoint blob
func updateCheckpointForBlob(url string, ctx context.Context, credential *azidentity.DefaultAzureCredential) {
zap.L().Info("Last accessed blob", zap.String("blob name", lastAccessBlob))
// Create a client
containerName := "checkpoint"
client, err := azblob.NewClient(url, credential, nil)
handleError(err)
// Check if the checkpoint blob exists
checkpointBlobName := "checkpoint.txt"
_, err = client.DownloadStream(ctx, containerName, checkpointBlobName, nil)
if err != nil {
if strings.Contains(err.Error(), "BlobNotFound") {
zap.L().Warn("Checkpoint blob does not exist, creating it", zap.String("blob name", checkpointBlobName))
// Create the checkpoint blob with the last accessed blob name
_, err = client.UploadBuffer(ctx, containerName, checkpointBlobName, []byte(lastAccessBlob), &azblob.UploadBufferOptions{})
handleError(err)
zap.L().Info("Checkpoint blob created successfully", zap.String("blob name", checkpointBlobName))
} else {
handleError(err)
}
} else {
zap.L().Info("Checkpoint blob exists, updating it", zap.String("blob name", checkpointBlobName))
// Update the checkpoint blob with the last accessed blob name
_, err = client.UploadBuffer(ctx, containerName, checkpointBlobName, []byte(lastAccessBlob), &azblob.UploadBufferOptions{})
handleError(err)
}
zap.L().Info("Checkpoint updated successfully", zap.String("blob name", checkpointBlobName))
}
func getLastCheckpointForBlob(url string, ctx context.Context, credential *azidentity.DefaultAzureCredential) {
// Create a client
containerName := "checkpoint"
client, err := azblob.NewClient(url, credential, nil)
handleError(err)
// Download the checkpoint blob
checkpointBlobName := "checkpoint.txt"
downloadedCheckpointBlob := bytes.Buffer{}
res, err := client.DownloadStream(ctx, containerName, checkpointBlobName, nil)
// Check if the checkpoint blob exists
if err != nil {
if strings.Contains(err.Error(), "BlobNotFound") {
zap.L().Warn("No checkpoint exists!", zap.String("blob name", checkpointBlobName))
} else {
handleError(err)
}
} else {
retryReader := res.NewRetryReader(ctx, &azblob.RetryReaderOptions{})
_, err = downloadedCheckpointBlob.ReadFrom(retryReader)
handleError(err)
err = retryReader.Close()
handleError(err)
zap.L().Info("Checkpoint blob downloaded successfully", zap.String("blob name", downloadedCheckpointBlob.String()))
lastAccessBlob = downloadedCheckpointBlob.String()
zap.L().Info("Last accessed blob from checkpoint", zap.String("blob name", lastAccessBlob))
}
}
func main() {
url := "https://somestorage.blob.core.windows.net/"
containerName := "general"
ctx := context.Background()
// Create credentials
credential, err := azidentity.NewDefaultAzureCredential(nil)
handleError(err)
zap.L().Info("Checking for an existing blob checkpoint prior to managing blobs..")
// Check for an existing checkpoint early on
getLastCheckpointForBlob(url, ctx, credential)
zap.L().Info("Application started, waiting for signals to shutdown gracefully..")
// Notify the application of the below signals to be handled on shutdown
s := make(chan os.Signal, 1)
signal.Notify(s,
syscall.SIGINT,
syscall.SIGTERM,
syscall.SIGQUIT)
// Goroutine to clean up prior to shutting down
go func() {
sig := <-s
switch sig {
case os.Interrupt:
zap.L().Warn("CTRL+C / os.Interrupt recieved, shutting down the application..")
// Update last checkpoint for the blob
updateCheckpointForBlob(url, ctx, credential)
os.Exit(0)
case syscall.SIGTERM:
zap.L().Warn("SIGTERM recieved.., shutting down the application..")
// Update last checkpoint for the blob
updateCheckpointForBlob(url, ctx, credential)
os.Exit(0)
case syscall.SIGQUIT:
zap.L().Warn("SIGQUIT recieved.., shutting down the application..")
// Update last checkpoint for the blob
updateCheckpointForBlob(url, ctx, credential)
os.Exit(0)
case syscall.SIGINT:
zap.L().Warn("SIGINT recieved.., shutting down the application..")
// Update last checkpoint for the blob
updateCheckpointForBlob(url, ctx, credential)
os.Exit(0)
}
}()
// Manage blobs
manageBlobs(url, containerName, ctx, credential)
// Update last checkpoint for the blob
// This will run after manageBlobs() completes - this would be a "typical" succesful application run
updateCheckpointForBlob(url, ctx, credential)
}
Retrying failed jobs
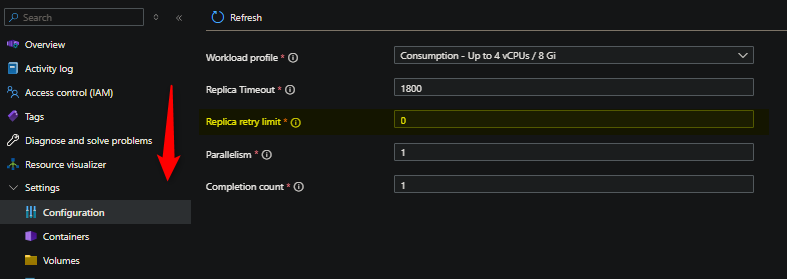
You can make use of replicaRetryLimit to retry a pod/replicas apart of a specific job execution if it gets marked as a “Failed” status. This typically means a container in the job pod has exited. This could be for any number of reasons - reviewing logging, and specifically application logging to see what occurred, should always be done.
For information on this, see Job settings. The below image shows where to find this in the portal for a Container App Job
Additionally, in terms of application processes failing with fatal errors or exceptions - proper error handling is always key for any of the sections called out in the wiki.

