Container Apps - Demystifying restarts
This post will discuss some behavior surrounding “restarts” on Azure Container Apps.
Overview
There may be times in logging, or maybe, custom alerts (if set up), that indicates a Container App restarted. Typically one of the first thoughts is “why”.
Note, this post will not nessecarily go into troubleshooting regarding any adverse reactions to restarts. But rather explain some of the potential reasons why this may occur and behavior of it.
“Restart” behavior
Since Container Apps is inheritly Kuberentes-based - and given the fact that application(s) run as a pod or replicas - a “restart” is a bit different than what be thought of as restart an existing container.
When a Container App is restarted - such as through the Revision -> “Restart” option (but also for the reasons listed in “Restart reasons” below), this ends up creating a new pod or new replicas. This does not restart just only a container or containers in the pod/replicas at the time and retain those specific pod/replicas. New pod/replicas (and thus new containers) will be created.
Again, given that this is inheritly a kubernetes concept - and pod/replicas are the “smallest schedulable unit” - we’re technically not operating at a per-container basis, when it comes to restarts.
When a “restart”/pod or replica movement does occur, it follows the below approach:
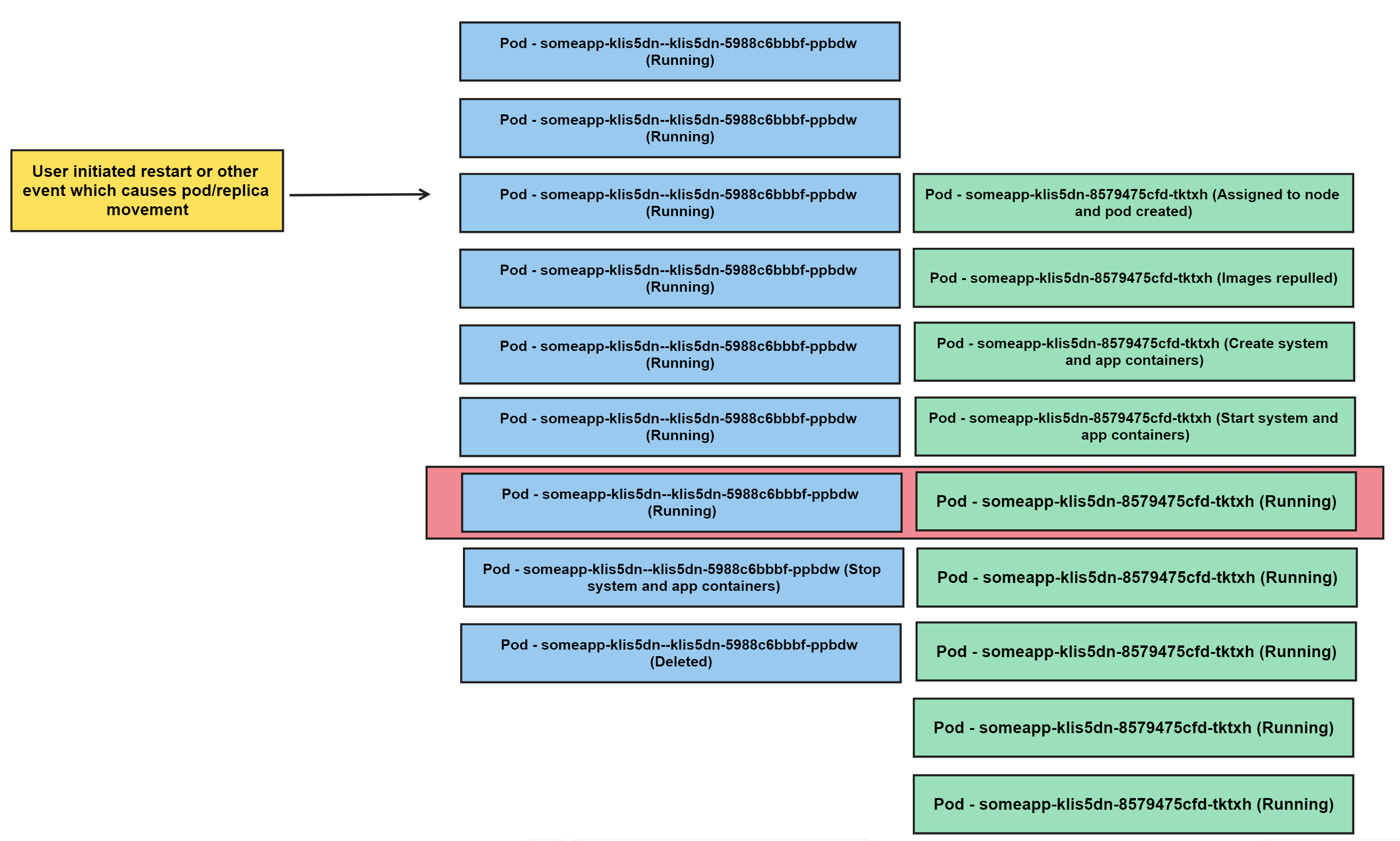
- Pod
someapp-klis5dn--klis5dn-5988c6bbbf-ppbdwis running - An event explicitly restarts the revision, or some other event occurs that creates a new pod
- New replica
some-appklis5dn-8579475cfd-tktxhis assigned to a node, the pod is created, the containers created, and the containers start:Replica 'some-appklis5dn-8579475cfd-tktxh' has been scheduled to run on a node.- Images are repulled
- Create system and app containers
- Start system and app containers
- Containers in pod
someapp-klis5dn--klis5dn-5988c6bbbf-ppbdware stopped - Pod
someapp-klis5dn--klis5dn-5988c6bbbf-ppbdwis deleted
What scenarios does this apply in?:
- When deploying a new revision (eg. deploying to an application which does a Revision Scope Change), or, explicitly creating a new revision
- When using the “Restart” option on a new revision
- Platform upgrades / node movement* (See the Node movement section below for specifics/caveats on this)
The red box in the foreground shows the concept of “no downtime” deployments where at a brief point in time there are two (2) replicas running.
This is why in certain views you may see a brief increase in replica count in these kinds of scenarios.
This can also be seen in the ContainerAppSystemLogs_CL or ContainerAppSystemLogs Log Analytics/Azure Monitor tables and focusing on the ReplicaName_s column. You’ll notice the change in pod or replica names and event activity like:
TimeGenerated Log_s ReplicaName_s
1/11/2024, 7:23:21.206 PM Replica 'some-app--v8yb5cv-68cf9bd595-vqwrp' has been scheduled to run on a node.
1/11/2024, 7:23:26.855 PM Pulling image "mcr.microsoft.com/k8se/quickstart:latest" some-app--v8yb5cv-68cf9bd595-vqwrp
1/11/2024, 7:23:28.297 PM Successfully pulled image "mcr.microsoft.com/k8se/quickstart:latest" in 1.111535414s (1.11154593s including waiting) some-app--v8yb5cv-68cf9bd595-vqwrp
1/11/2024, 7:23:28.297 PM Created container simple-hello-world-container some-app--v8yb5cv-68cf9bd595-vqwrp
1/11/2024, 7:23:28.297 PM Started container simple-hello-world-container some-app--v8yb5cv-68cf9bd595-vqwrp
1/11/2024, 7:23:31.527 PM Stopping container simple-hello-world-container some-app--v8yb5cv-6cbc7f9c8b-fg8vn
Health Probes failing after restarts:
After a restart-like event, you may see something like readiness probe failed: connection refused. For the context of this post, this is not talking about most of what is described in Container Apps: Troubleshooting and configuration with Health Probes
Potentially, if you notice and compare the Replica/Pod name - you may actually see that this is occuring for the previously shutdown containers and deleted pod. Below is an example via ContainerAppSystemLogs_CL for a pod being removed due to a restart.
TimeGenerated Log_s ReplicaName_s
1/11/2024, 7:23:31.527 PM Stopping container simple-hello-world-container
1/11/2024, 7:23:37.012 PM readiness probe failed: connection refused my-app--v8yb5cv-6cbc7f9c8b-fg8vn
1/11/2024, 7:23:32.009 PM readiness probe failed: connection refused my-app--v8yb5cv-6cbc7f9c8b-fg8vn
1/11/2024, 7:23:42.471 PM readiness probe failed: connection refused my-app--v8yb5cv-6cbc7f9c8b-fg8vn
What is happening is that probes are being sent to these containers after being shut down from a restart-like event. This is harmless and can be ignored.
Restart reasons
- Management operations, such as:
- Creation of new revisions (which creates a new pod/replicas)
- This can be manually done to explicitly create a new one
- Any changes to revision scope properties
- Common themes would be changing the image or tag, environment variables, and others
- Scaling up
- Note, that scaling out would appear as if new replica was starting and not restarting in the sense of old pod/replicas being shutdown and new ones being created
- Restart of a revision
- Creation of new revisions (which creates a new pod/replicas)
Node movement:
Kubernetes-based applications run on nodes - which is essentially just some type of server (a VM, physical machine, etc.). If coming from Azure App Service - there may be familiarity with instances and platform upgrades.
This same compute concept applies to Container Apps. At times, there may be platform maintenance or node “movement” for other reasons - which is also called out in Azure Container Apps environments
This will also appear to look like a restart. To prevent any potential issues in these cases - it’s typically a good idea to run >= 3 replicas or more. Why?:
- Running at this amount will try to gaurentee a subset of created replicas. Think, PDBs (Pod Disruption Budgets). However, it’s important to understand PDBs and this scenario do not care about the state of your container/application - it cares if a replica has been created (which is not tied to the state of your application).
- Example: If you have 3 replicas and a platform upgrade undergoes, and during rolling upgrades, at least 1 replica is created - but the application container in that replica happens to fail (either consistently failing health probes and thus being restarted, or crashing/exiting/failing to start, or many other scenarios) - then there is the chance you may see a very brief availability issue, assuming that neither of the other 2 replicas and containers in them were started yet
- The above example is an extreme scenario - but is an example of the platform functioning correctly (and also something you’d see regardless, outside of ACA when using Kubernetes in general)
- In almost all cases, simply having multiple replicas helps ensure chances at redundancy - since replicas will be scheduled across nodes (assuming you’re not set to a minimum/maximum of one (1) node on a Dedicated Workload Profile) - which in that case, also a minimum of three three (3) nodes for applications is recommended.
- Not following any of the above (eg. 1 replica on 1 node, with Health Probes set to values that don’t “fit” the application, amongst other bad practices) may have a slight chance to be seen that a replica is evicted during some kind of immediate node movement or node issue where the net-new replica is not created just yet.
Note, that in certain cases you may also see something like 0/4 nodes are available (although 0/x count will vary) - in most cases, this likely does not affect the application, and can rather be a sign of node movement and pod/replicas being rescheduled.
Back-off restarts:
This is probably one of the closest concepts to a classic container restart in a Kubernetes based environment. When back-off restarts occur, this means the container is consistently failing to be started.
- An example of this would be consistently exiting upon startup
This will appear in ContainerAppSystemLogs_CL or ContainerAppSystemLogs - this is a product of a failing container and not an explicit user action technically.
When this occurs, the container will attempted to be restarted a defined number of times before the pod/replica is marked as failed. This may look like the following in the above Log Analytic / Azure Monitor tables:
Log_s ReplicaName_s Reason_s
Persistent Failiure to start container some-app--6v70gws-995846dc9-jbvdz ContainerBackOff


