Container Apps and Failed Revisions
This post will cover some more common scenarios on why a Container App ‘revision’ may show as ‘failed’.
With the introduction of Container Apps brings the notion of a revision. Revisions allow you to manage different ‘versions’ of your application. This concept essentially follows the same idea that could be found in Kubernetes. For further reading on revisions and their modes, review this link here.
When you may see failed revisions
Failed revisions may show in some scenarios like:
- The initial Container App deployment to an environment.
- Changes to an existing Container App, like its configuration under the
templatessection, which will create a new revision - Creating a new revision from an existing Container App, and doing changes or updates from here, for the new revision.
It’s important to note that these scenarios can present themselves for multiple reasons. Such as application code issues, container misconfiguration, or others. Below will cover a few scenarios.
Incorrect Ingress
If deploying an application to Container Apps and using external ingress, the targetPort must match the port that’s exposed in the Dockerfile (or what port your application is listening to).
If this is not correctly set, such as setting Target Port to 80, yet the application is listening on 8000, this will caused a failed revision, either upon deploying initially or when creating a new revision and updating this.
For example, this application is deployed to listen on port 8000, but we have 80 set as the target port:
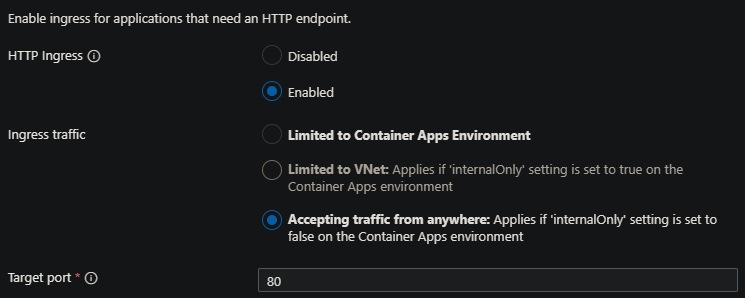
Since the container will never successfully return a response due to the mismatched ports, we can see the revision is marked as failed.

The solution in this case would be to set Target Port to what’s exposed in your Dockerfile (or what port your application is listening to).
See Troubleshooting ingress issues on Azure Container Apps for further information on ingress-specific troubleshooting.
Important: If you are running your application as a background-service and/or do not expect to listen for HTTP traffic, then do not enable Ingress, as it expects a HTTP response back from the container to determine its health. This type of scenario will also cause a revision to be marked as failed.
Health Probes
Health Probes can be configured to determine the container health in 3 different ways (startup, readiness and liveness). If these are misconfigured or the application doesn’t respond to what is set for these, a revision will be marked as failed. For example:
- Setting the wrong
Portin the Readiness probe - Setting a path that returns a response outside of a 200 - 400 range (ex., 404) in the Readiness probe:
- Doing either of the above for Liveness probes.
- If the application doesn’t expect HTTP traffic then this should be disabled as this can also cause failed revisions since no HTTP response would be sent back from the container.
Note: This also may show that the container is indefinitely provisioning

See Container Apps: Troubleshooting and configuration with Health Probes for more specific Health Probe-based troubleshooting.
Running a privileged container
Privileged containers cannot be ran - this will cause a failed revision. If your program attempts to run a process that requires real root access, the application inside the container experiences a runtime error and fail.
NOTE: Note that the user ‘root’ in containers is normally mapped to a non-priviledged user on the host - ultimately running as a non-proviledged container. This is due to Docker itself dropping cretain CAP_ capability keys by default and design and the fact that user namespaces are at play.
Additionally there is no option to run docker run.. <args> to allow this in Azure Container Apps, which is by design, nor is there any option exposed to change the priviledges set for Kubernetes underneath.
Application errors
Consider the following: A Docker Image was built and pushed to a registry, this same image is used in a Azure Container App - either in a brand new created Container App or a new revision using the updated changes that were pushed to the tag.
When running the application, after a scenario like the above, we see the following in our Log Analytics workspace:
Error [ERR_MODULE_NOT_FOUND]: Cannot find package 'dotenv' imported from /app/server.js
An application issue like this would cause the container to exit and cause a failed revision. Essentially, an unhandled exception or error that causes the container to exit (process to terminate) will present itself as a failed revision.
In these scenarios, you can validate if your application is causing this with either Log Analytics, using Container App specific tables, Azure CLI, or Log Stream.
NOTE: Note that Log Stream may not show any output if the container is failing. If this is the case, use Log Analytics to double check if the application is writing to stdout/err.
For more application-specific troubleshooting, review the following posts:
- Container Apps - Troubleshooting ‘ContainerCreateFailure’ and ‘OCI runtime create failed’ issues
- Container Apps - Backoff restarts and container exits
Invalid options or unreachable registry
Image/Tag values
Another possibility of a failed revision if passing bad or incorrect image/tag combinations.
However, in most cases (depending on how this is deployed), validation will fail the deployment prior to this stage. For example, doing this through the portal:
Portal:
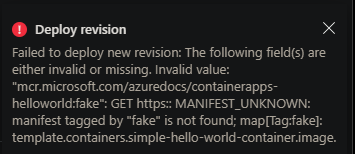
Template-based deployment:
{"status":"Failed","error":{"code":"DeploymentFailed","message":"At least one resource deployment operation failed. Please list deployment operations for details. Please see https://aka.ms/DeployOperations for usage details.","details":[{"code":"BadRequest","message":"{\r\n \"code\": \"WebhookInvalidParameterValue\",\r\n \"message\": \"The following field(s) are either invalid or missing. Invalid value: \\\"mycontainerregistry.azurecr.io/container-apps-scaling-examples-http:latest2\\\": GET https:: MANIFEST_UNKNOWN: manifest tagged by \\\"latest2\\\" is not found; map[Tag:latest2]: template.containers.containerappsscalingexampleshttp.image.\"\r\n}"}]}}
If this scenario is suspected to be the case - ensure the Image and Tag combinations are valid.
Networked environment Secondly, if the image is failing to pull due to either misconfiguration or an environment issue (eg., Networked environment - Firewall is blocking access to the Container Registry, or DNS lookup on the registry is failing), this may present itself as a failed revision as well - as the Image itself would not successfully pull.
In this scenario, review if it’s possible to pull this publicly, and if so - work backwards to troubleshoot the environment itself.
The below documentation can be reviewed for help in configuration:
- Networking - Architecture Overview
- Deploy with an external environment
- Deploy with an internal environment
- Securing a custom VNET
- Customer responsibilites when using a VNET
Further reading:
For a deeper look into troubleshooting image pull failures, see Container Apps: Troubleshooting image pull errors
Resource contention
Aggressive scale rules or applications that are consuming a large amount CPU and/or Memory, for example, and consistently enough - could potentially put the Pods that are running these workloads into a state that causes the application(s) to crash.
Underneath the hood, resources will be attempted to be allocated to provision these - however, if the scenario occurring is always using a large amount of resources (eg., Memory - if the combined limit for the Container App Pod that is configured is being hit consistently), this can cause the workloads to fail to be provisioned.
In scenarios like these - the Metrics blade under Monitoring can be used to check metrics such as Requests, Replica Count, CPU, Memory, and others.
If aggressive scaling is done, review these rules and their criteria for what is triggering these events.
Environment is in an unhealthy state
If an environment is in an unhealthy state, for example, due to:
- Using a Consumption-only environment with networking such as UDR’s that inheritly may “break” the environment - see Control outbound traffic with user defined routes
- Azure Policies that may affect environment upgrades or management operations. For example, an Azure Policy on tags - such as blocking any kind of tag or metadata change. This can cause environments to break when a environment or it’s managed resource groups are upgraded/updated.
- etc.
Since this would cause the environment to go into a Failed or generally unsuccessful “Provisioning State” - user operations on the environment or specific apps will likely fail across the board. If you happen to just only focus on creation of new revisions - it may appear that only revisions are “broken” or “failed” - whereas it’s a wider spread problem.
Further reading
For other informational posts related to Azure Container Apps - see the azureossd.github.io - Container Apps Category section.


